Code Review Is About to Break
I’ve been on a research sabbatical for a little over a year now, building a new framework for teaching how harmony works in popular music (you can see an early demo at modalinterchange.com). I’m an amateur musician, and my sabbatical’s been busy — I’ve been studying jazz, Balkan brass, funk, and the New Orleans second line tradition — and I’ve been gigging with a number of brass bands. On my way to New Orleans for Mardi Gras, I stopped in at the Pragmatic Engineer Summit — Gergely Orosz’s conference on the future of agentic engineering.
It’s been a good break. The whole time though I’ve been closely tracking from the outside what people have been able to do at the frontier of agentic engineering (and trying some of it myself). The summit was for engineering leaders and senior engineers, every talk was about AI, and I expected it to show me how weird things were starting to get in the industry. So I was pretty shocked at how normal everything felt.
I went to dinner after the conference with some friends I made there. They asked me what I thought, and I said, “I kind of expected the industry would look more different”. They asked, “compared to what”? And I said, “well, compared to what I expect is coming”.
What I saw at the summit
I went to a talk by Uber’s Ty Smith (Principal Engineer) and Anshu Chadha (Director of Engineering for its Developer Platform org). Here’s the talk on YouTube. My last job was in DoorDash’s developer platform org, leading similar work, so this is a talk I really wanted to see.
At one point, Anshu said to us:
The tech that Ty talked about, I’ve seen it in action, it’s magic. I ran a demo session with some of my VPs and within 24 minutes I had 4 VPs land code for the first time in years.
Executives across the industry are discovering Claude Code (many of them over the winter holidays). My sympathies to all the tech leads who’ve had to talk these execs down from torpedoing their Q2 plans and explain that what we do is not vibecoding. But they’re seeing what’s happening to the cost curve of engineering work.
The pattern I kept seeing was: lots of adoption experiments, but not a lot of fundamental rethinking.
The opening talk of the summit was a Q&A, with Tibo Scottiaux, the engineering manager of the Codex team at OpenAI, and Vijaye Raji, their CTO of Applications. They mentioned that at OpenAI, designers are shipping more code than engineers were 6 months ago. PMs will make prototypes and validate assumptions before approaching engineering, and prototypes are more complete than they used to be. That caught my attention. It reminds me of a point Jaana Dogan, a principal engineer at Google, has been making: the move now is to build PoCs before ever asking for budget, writing a design doc, or asking for permission.
Aside from the Codex team though, I got the distinct impression that what people were presenting felt familiar, and normal, like we still were thinking of LLMs primarily as assistants, in the “smart autocomplete” sense that started with Github Copilot. Orgs were trying things but nobody seemed confident about what was actually working — outcomes and adoption diverged a lot.
What I did see was a lot of plugging LLMs into CI (continuous integration). That seemed to be the one thing everyone was working on. And there was also a growing awareness that all this code that’s being generated has to be reviewed and understood by someone, and the reviewers are being increasingly overwhelmed.
The overhang
What I’ve been telling my friends outside the industry is that there was a serious step-change in how good coding models are, in late November of 2025, with the release of Claude Opus 4.5 — heavily RL’d on its coding harness, in a way that previous models weren’t (or at least that’s my best read on what changed). The paradigm that previously sort-of-almost worked, now actually really works. Andrej Karpathy says he’s stopped writing his own code entirely. I didn’t get the sense that a lot of the attendees and speakers had really internalized this yet. I didn’t see much reckoning with how fast things are moving.
Tibo told us:
I keep talking to this researcher on the team who’s actually training the models, and he’s like, ‘every time I think I’m more capable than codex, I figure out that I’m wrong and I just didn’t prompt it right, or I hadn’t set it up in the right way.’
I found a surprising gap between what the industry seems to be asking of LLMs, and what they’re really capable of now. It’s like we’re bolting LLMs onto existing practices, assuming we’re still going to be using yesterday’s models. People are still thinking of them as interns. People are still pasting from chat windows.
No. This mindset doesn’t work anymore. Treating LLMs like ticket crunchers is leaving a lot on the table. Treating them like “just tools” will limit you to “just tool” results. I get much better results from treating the model like a partner working on an interesting problem space, where we can iterate, it can develop its own understanding, and where it can search and explore and verify its work. I push back against my agents constantly. If the work doesn’t hold up, they try again. Tibo made a related point about the Codex team’s working style: for long-running tasks, they invest their time prepping Codex’s environment and scaffolding before the agent starts writing code.
And so I’m forced to conclude that capabilities are no longer the dominant constraint for a growing share of engineering work, like they were in 2025. Context and compute are the new constraints. Sure, long horizon tasks still fail, models will still confidently do wrong things, but those failures are increasingly addressable with more context, more compute, more scaffolding. You don’t need to wait for the next model release. And by calling compute a constraint, I don’t mean “let’s all find a way to do this at a lower cost” — I mean the opposite, actually: everyone needs to ask themselves how they can spend more compute to get better results. Teams that don’t learn to budget compute intentionally will throttle themselves into “LLMs don’t work”.
I’ve seen a widespread assumption, inside the industry and out, that what happened is that coding got easy. In a sense, obviously, yeah, big time. But this is misleading. I think what’s happened instead is that the floor of engineering work just moved up a level of abstraction. And what we’re just starting to find is that the cognitive load at that level is brutal.
There was a slide in Laura Tacho’s talk that just said:

That caught me off-guard! In her talk, she explained that most companies are stuck in what she called “high adoption, low transformation”. Few companies are anywhere near the frontier of LLM usage patterns. And their outcomes reflect that: some orgs have seen production incidents drop in half. Others have seen them double.
That’s an enormous gap.
That variation tells me there’s a massive capability overhang. When outcomes vary this much between companies, the models aren’t the bottleneck. This is an organizational design problem.
With hiring frozen across the industry, engineers aren’t moving between companies like they normally would, so practices aren’t cross-pollinating.
The one topic that kept coming up, in every talk and in every conversation I had: code review. Here’s what’s happening right now: everyone’s spending more time planning, reviewing code, reviewing design docs, reviewing their own agents’ work. It shouldn’t surprise anyone that many engineers were drowning in review even before this. But it’s poised to get a lot worse. And reviewing was always harder than coding.
What’s happening is not just cheaper code generation, we’re actually moving the bottleneck into review and integration.
Code review
Code review is trying to answer a lot of questions all at once: will this break prod? (if it does, can it be rolled back safely? what’s the blast radius?). Is this the right design, is this going to trap us architecturally? Is this the right thing to build, with respect to the plans / spec / business / etc.? Is this easy for a human to understand six months from now at 2am? It’s not a compact problem.
Uber’s Developer Platform built a code review pipeline to manage the load of their higher PR volume. Here’s the diagram they showed us:
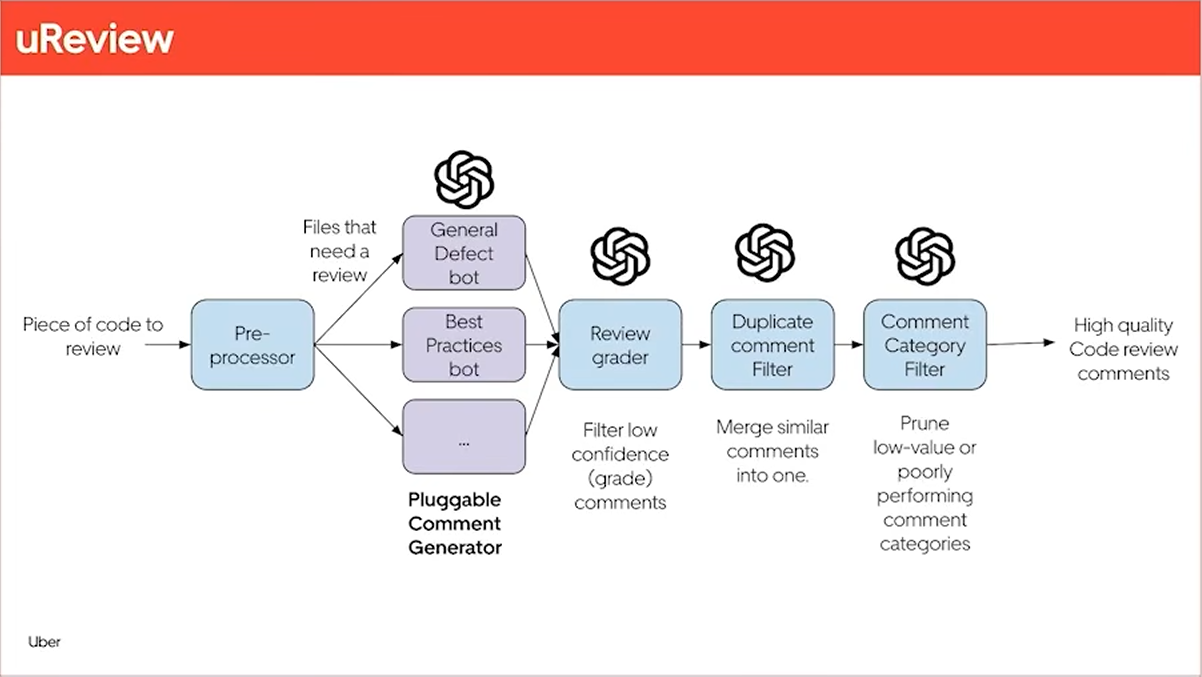
They’re getting good results: they say 60% of these LLM code review comments get addressed. After several years working on a search engine, I can’t help but see ranking and relevance as the heart of this — this sounds like good work, and a good place to start.
About a month after the summit, Anthropic released a Code Review product that takes a similar approach — lots of subagents focused on specific aspects, whose outputs are fed to synthesis agents. Many companies went for the “integrate LLM reviews into the pull request CI” approach in 2025. It gives you something legible to ship that stays within budget.
But I’d bet for the PRs that really matter, you want a frontier model with a max reasoning budget generating your review, not cheaper models that require several stages of cleanup.
And even with better models, this is still just giving us leverage on yesterday’s paradigm. They’re trying to generate human-addressable comments on a diff. These reviewer agents — can they run tests to see if their suggestions pass? Can they deploy a build to a test environment and load test it?
Platform teams have been trying to build code review tools with tight constraints that make this impossible. Too little compute, too little context, and nowhere for agents to experiment.
I’ll get specific. If you’re dissatisfied with the LLM code reviews you’re getting at your company, let me ask you:
- Are you using the best review model available (GPT-5.4 at the time of writing) with the “extra high” reasoning budget?
- Are you sending it as much relevant context as you possibly can?
- Are you willing to wait 10 minutes for the review to finish?
- Are you willing to spend $5 to $10 in compute on a review?
No? Then don’t be surprised that what you’re seeing is underwhelming. And if you’re a platform engineer, don’t be surprised that adoption is slow.
But the deeper problem coming for all of us is that throwing more humans at reviewing this increased volume of code will not scale.
Coding, at least, you can do in a flow state. High-stakes, high-context code review? It’s hard. It’s hard to do at the high quality level you need to avoid causing major production incidents. And it’s hard in the sense that reviewing implementations, reviewing designs, and deciding what to do about all of it — those are all cognitively intense activities. Software engineering has always been cognitively intense, but the level at which we’re starting to work is something else. No one can sustain that for more than a few hours a day. We made it work when it was just humans producing code. But agents producing 2x the volume are going to break this.
I was talking to a platform engineer at a fairly large well-known tech company. He told us how he went through service logs, searched for a common type of crash, and then had LLMs fix those crashes in a bunch of different services. Then he sent PRs for the service owners to review, and many of them just sat there for weeks. (This’ll be a familiar story to every platform engineer. You can learn a lot about your org very quickly by how responsive each team is to external contributions.) Code review was already the bottleneck for many types of engineering work. The industry is currently scaling pressure on the bottleneck.
A lot of our cultural assumptions about what code reviews are even for are going to be challenged this year. And honestly, it’s about time — engineers should not have to be human linters anymore.
The false dichotomy
Many teams are already feeling squeezed between two bad options:
- Ship fast and cause incidents
- Ship slow and drown in the review queue
And to be clear, by “slow” I mean the shipping speed that was normal in 2024. That’s slow by the standards of what’s possible now.
As everyone knows, you can always just spend less effort reviewing each PR. We’ve all been on both sides of this. It’s 4:30 PM, your brain is fried…that PR’s got unit tests, it’s got good vibes, no obvious problems, you trust the author, … whatever, LGTM.
Code review incentives are already misaligned with our work. In many orgs, reviewing code does not count toward your performance review. In many places there’s a favor economy in place for getting code reviewed by the right people. This is going to get worse, and fast.
Marc Brooker, a distinguished engineer at AWS, once analyzed the root causes behind a huge number of production incidents, and found that the #1 factor for preventing incidents was code review. I watched that talk when I started at Amazon in 2016, and it stuck with me. I’ve spent a lot of my career so far working on reliability, and what’s happening right now makes me nervous.
Speaking of Amazon: there was a notable AWS outage recently. [Techradar]
- An agent, using one of Amazon’s internal Kiro models, decided to delete a whole production environment to solve a problem
- It caused a huge incident that took 6 hours to recover from
- In response to this and other similar incidents, there’s a new rule: AI-assisted code has to be reviewed by senior engineers
Why the agent had permission to delete a production environment is beyond me. But what this is saying is that junior engineers can still open PRs written by LLMs, seniors just have to review them all. I’m guessing most Amazon senior engineers were already overwhelmed with PRs to review. So, Amazon, for now, is choosing the “ship slow” end of the trade-off.
But slop is not an inherent property of agentic engineering. It’s a result of underspending and underinvestment in infra. It’s worth noting that Amazon’s Kiro models are not frontier models.
And what’s more: companies will not be able to choose “ship slow” forever. It’s not a stable equilibrium. Engineers are judged on their output, both in their current roles and in interviews for the next one. You can’t effectively tell thousands of people to “slow down and focus on reliability” and expect everyone to go along with that indefinitely.
Not everyone is choosing “ship slow”. Other large companies are going the opposite direction: top down mandates for AI usage, that’s tracked and tied to performance reviews. But from what I’m hearing, the tooling is substandard. The engineering culture hasn’t changed. Often the top-down mandates are paired with layoffs. The message is not “let’s take advantage of this huge increase in leverage”, it’s “we’re going to work you to the bone to make up for your teammates we let go”. These orgs will lose their best engineers to ones that are actually getting agentic engineering right. As a platform engineer I’ll say this: you should not have to mandate that engineers use tools. That’s a warning sign. Mandates kill the feedback loop — if engineers can’t walk away from the platform, there’s no pressure to fix it. You need to make the tools great.
But none of these approaches address the real danger. What happens when we ship faster and faster while understanding what we’re shipping less and less?
I expect we’ll do a lot of this. The danger is opening ourselves up to not only more frequent small outages, which software companies have always had and have always budgeted for, but also a higher risk of huge gordian knot outages. The kinds of outages that no one has the context to fix quickly, the kinds of outages that cost you major customers, derail Q2 plans, and put leadership in front of the board explaining what happened. We’re deep into a world where the economy runs on 24/7 software. We are not going to be able to pull this ratchet back, where long outages are acceptable.
In the short term, having LLMs as the primary reviewers of code isn’t going to work either. The nastiest incidents that happen in production are not easy to catch in code review without a human who has deep context of both the system and the domain. Most of these problems are invisible from a diff.
But we need to do something. I think there’s a third option: invest heavily in making it safe to ship.
It’s worth pointing out that we’re already in a scary world. Most engineering teams only partially understand the systems they own. Except instead of agents, it’s engineers from 10 years ago who are all gone, who made their decisions in a totally different environment. But we need to ship. The question has always been: how safe is it to deploy changes in a system? We need the answer to be very.
So many teams in this industry are horrendously under-resourced when it comes to validation infrastructure. We’ve all been there. Broken tests everyone ignores. Manual deployment steps. Tribal knowledge needed to get load testing working. All of this is a bottleneck at a scale that it wasn’t before. So let’s fix all of that.
Reviewer agents need real environments where they can test their own suggestions. Load testing, integration testing, performance testing, this all needs to be available and automated by default, it can’t be locked behind institutional lore or 6-month capacity planning cycles. Our tolerance for broken tests should drop to zero now that LLMs can fix them.
We are building judgment infrastructure.
What the frontier actually looks like
The frontier is more accessible than people think. Last year, many startups learned the hard way that no amount of scaffolding could make a weaker model perform like a stronger one. Models were the limiting factor. But now that they’re as good as they are, you’d be surprised at how little setup you need.
For my personal projects, I have Opus 4.6 in Claude Code write the implementation. Then I have Opus gather up as much context as it can — test files, related files, the whole original file, the goals and assumptions, and (obviously) the diff itself — and send it to GPT-5.4 (on the extra-high reasoning setting) through a Claude Code skill. My prompt is dead simple: “you are a senior engineer doing a thorough code review…”. The real work here was writing the skill, i.e. telling Opus what context to gather and where to send it, which took maybe 10 minutes. Once GPT-5.4 has the review, it spends 10-20 minutes squirrelling away and usually comes back with something remarkably good. Then Opus judges the comments, decides what it thinks of each of them, and addresses the ones it feels it should, as I passively watch and give input where I think Opus needs it. This whole thing costs me maybe 50 cents. For production code I’d be happy to spend a lot more.
That’s the whole setup. The key here is that I use the best model available, give it as many reasoning tokens as I can, and give it as much context as I can.
And you can indeed find ways to spend more. Anthropic charges $15-$25 per review for theirs. It tells you where Anthropic expects inference spending to go, industry-wide.
Spending real money on inference is what makes this work. Below a certain level of spending, code review is essentially a different product. I’ve had some friends express sticker shock at the $15-$25, but senior engineers’ time costs a lot more than that, it’s just bundled with comp, right?
The Codex team’s practices were the only thing at the summit that really felt like the future to me. Tibo said that within the team, code review is mostly automated. Their next challenges are integration and deployment, and understanding user needs faster. Triaging their feature backlog to see what’s trivial to implement feels “almost free”.
Tibo has 33 direct reports. He says that with this structure, it’s unsustainable to have single-person bottlenecks. In my experience, single-person bottlenecks are usually reviews and approvals. There’s a mantra among the team: “hyperleverage yourself”. They’ll spawn agents in the background at the beginning of meetings to answer questions, and by the end of the meeting they’ll have answers. Instead of writing design docs they’ll build multiple approaches in parallel — trying is now cheaper than planning.
Vijaye Raji’s view is that looking at code is over — properties of systems, guardrails, and provability are what’s going to matter.
Most engineering orgs aren’t anywhere near this. Yet. I wouldn’t join a team that isn’t approaching this though — this is not an era where you can afford to waste years on 2024-era practices. Capabilities are moving fast — Anthropic’s system card for their next-generation model says it reviews code like a senior engineer — and we’re not about to have another 5 years of normal.
What to do
If you do nothing else this week, build a review skill into your coding harness, ideally from a different frontier model than the one who wrote the code.
At an org level: code review is about to be your biggest source of developer friction and you need to fund it accordingly.
The math on building tooling has flipped. In the old world, we used to ask, “will I do this enough times to justify automating it”? But even automated tasks need a human’s attention in order to run. Now that an agent can run the tooling, that constraint is gone. If you build it once, an agent can run it a thousand times without you. So: if Claude can’t solve your problem, ask yourself what context, tools, or data sources would be needed for Claude to solve it.
Invest seriously in token spending and great tooling. Your best engineers are looking for leverage, and will route around the tooling you give them in order to get it. They’ll demand discretionary spend. And if you make that hard, they’ll route around your org, by switching teams or switching jobs. Notice that the people at the top of OpenAI’s internal codex usage leaderboards were already the top researchers and engineers.
And if you need to sell this investment upward, the best piece of advice I heard at the summit was from Laura Tacho:
Here is a piece of very unconventional advice that I will give you: anything you were going to talk about with your leadership team about developer experience, just call it agent experience. And you’ll get money for it.
Looking forward
Let me zoom out: I’d strongly bet LLMs are not going to eat all of our jobs. Not until they’re good enough to eat everyone’s job, that is (and we have some time before that happens, if it does). As agents become better at managing software, our software is going to get more complex and we’ll need to manage more of it. Agentic engineering is hard. But it works, and we’re in an unprecedented era of leverage across the board. I think we’ll look back at the pre-2024 world and be shocked at how little engineering manpower the earth had.
And domain expertise amplifies the new leverage. Someone with deep domain knowledge directing agents might make 100 really good decisions in a week, vs someone with the agents but without domain knowledge making 100 mediocre decisions. If you’re a domain expert, and you notice you can now build what once took you a year in a few weeks with LLMs — just consider that not everyone can do it in a few weeks.
Later that day, I attended a roundtable on the future of knowledge work. I sat next to a VP. He told us that he didn’t know what to tell his teenager about how to prepare for a career anymore. No one at that table was confident predicting what things would look like more than 6 months out. And I remembered: the OpenAI speakers earlier in the day also wouldn’t make predictions more than 6 months out. Nobody I heard or spoke to at the summit was willing to.
The only thing I’m personally confident about is that the next few years won’t look like the last few. I would bet on capabilities continuing to increase. The way engineering work is structured will change fast. And that’s why 2024-era mental models are so dangerous, because they assume the future will be a smooth, linear continuation of the recent past. But huge paradigm shifts absolutely do not look linear. In big dynamic systems, it’s not one thing that changes — it’s everything and its relationship to everything else all at once. We’re only 4 months into this.